Next-Embedding Prediction Makes Strong Vision Learners
一句话
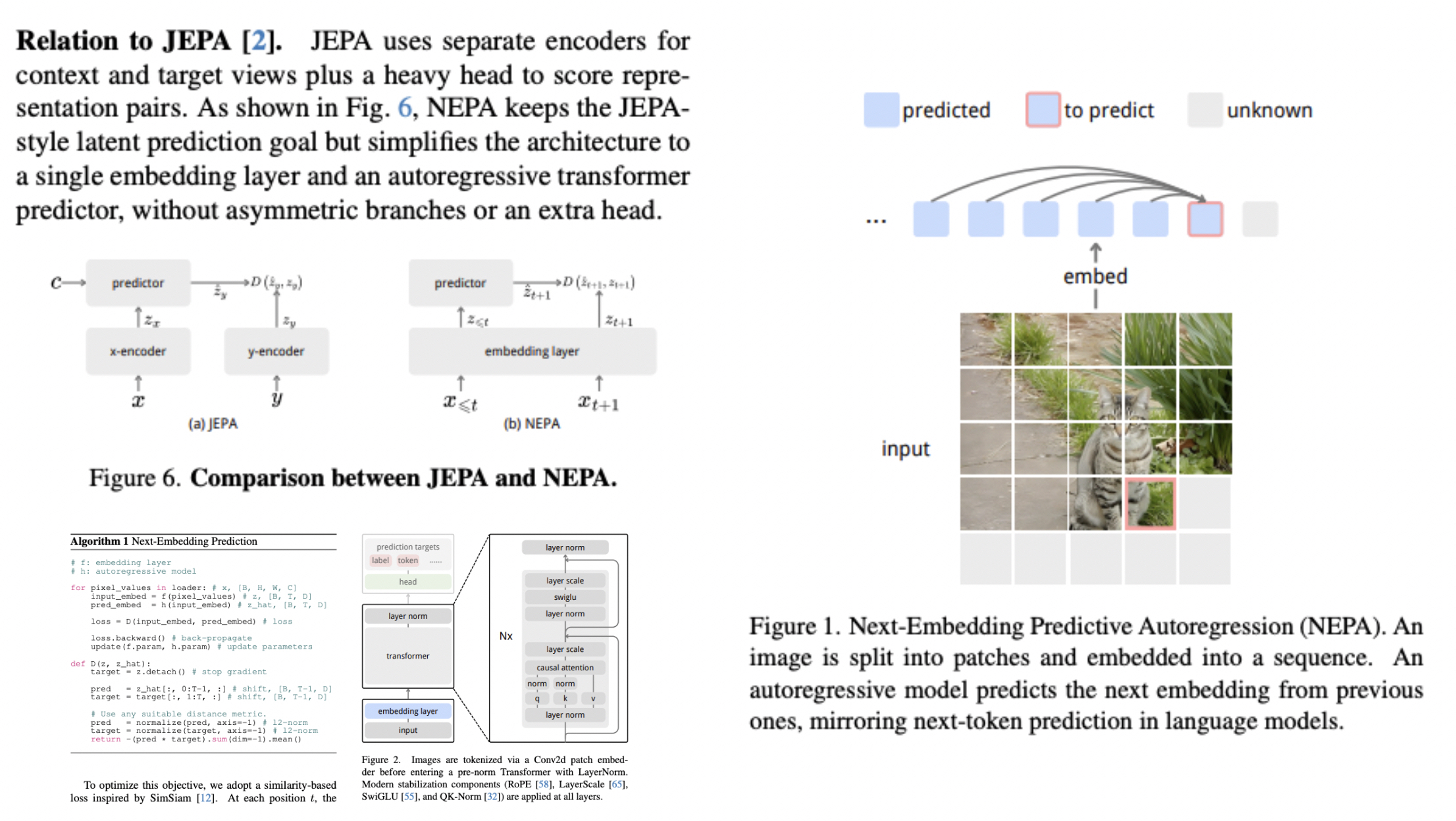
视觉Backbone预训练的方案,类似NTP,区别是预测Embedding,这个Embedding是图像过了EmbeddingLayer后的序列向量。训练的时候用causal attention,SFT的时候用bidirectional attention效果更好。
一张图
Written on December 19, 2025

记忆碎片