
Towards Scalable Pre-training of Visual Tokenizers for Generation
一句话
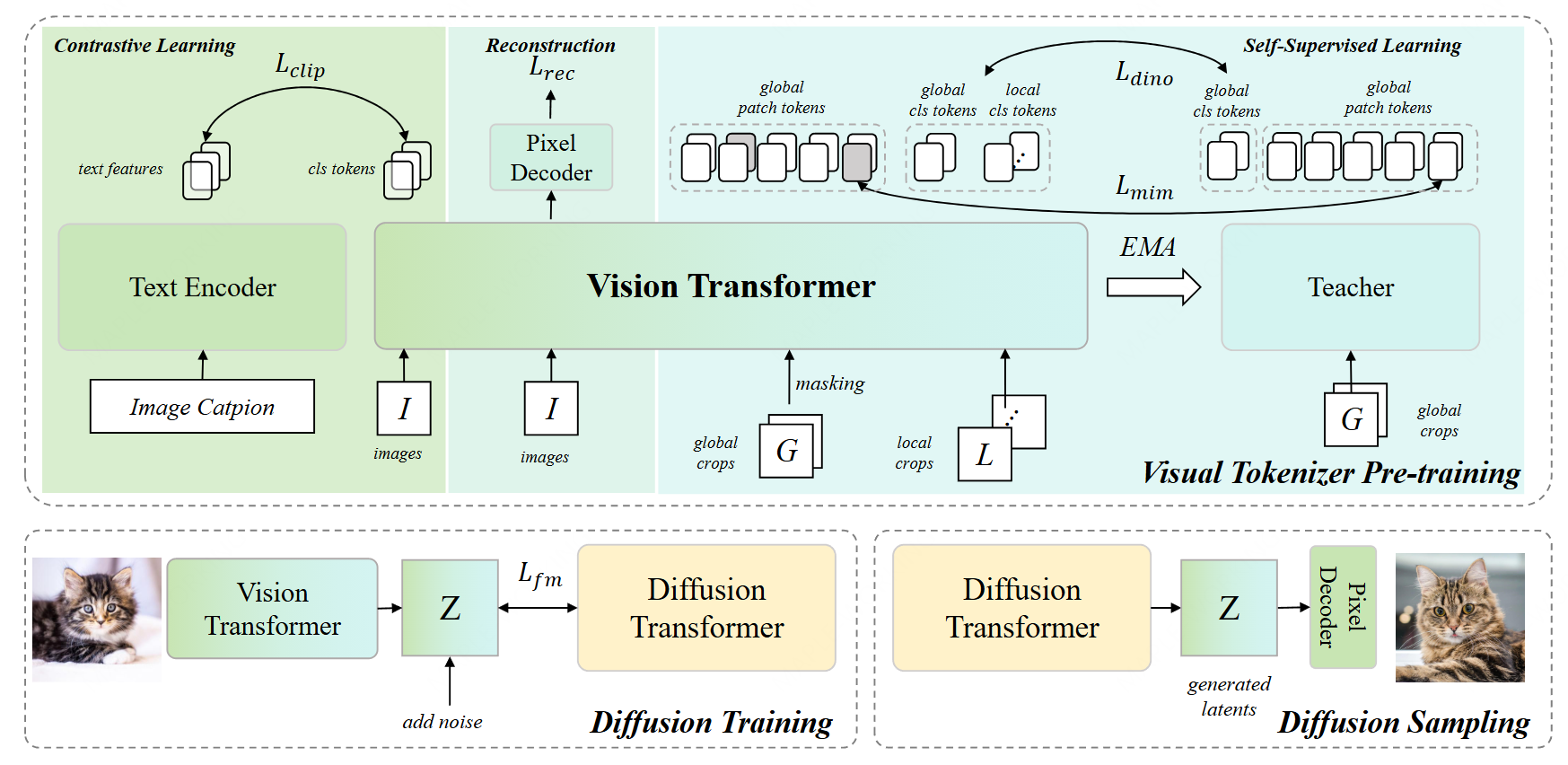
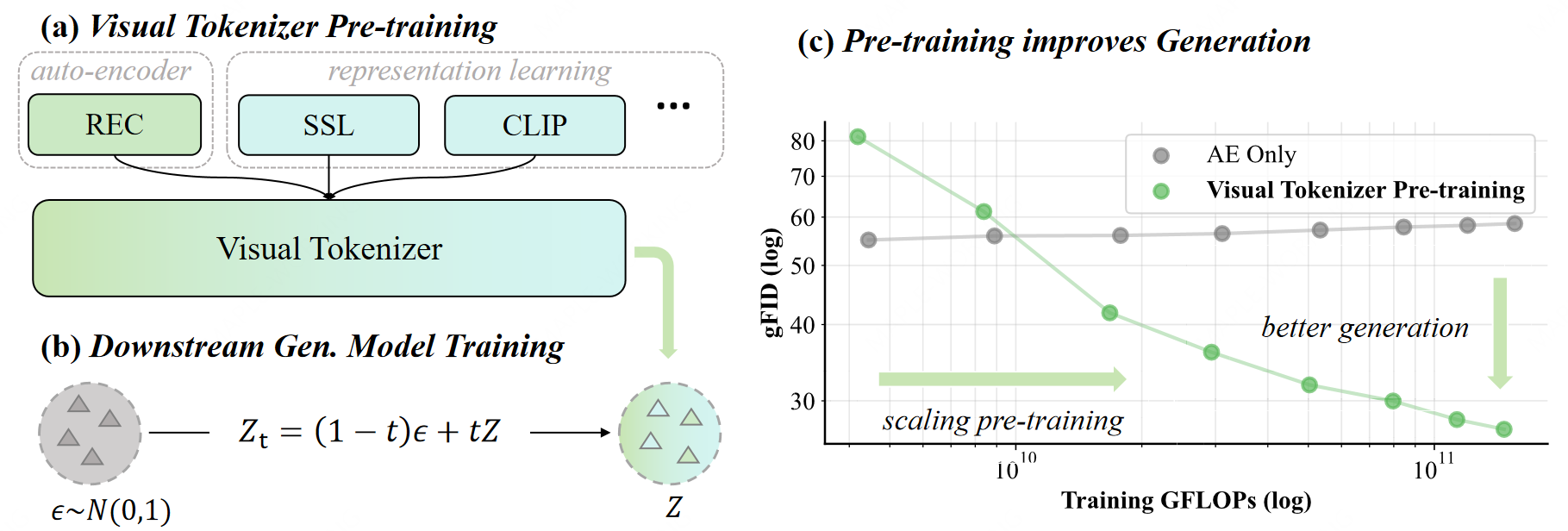
图像生成领域中的视觉分词器(Visual Tokenizer)预训练范式正经历关键变革。研究表明,以VAE为代表的、基于纯重建损失的视觉分词器,其潜在空间偏向于低层像素信息,在扩大预训练规模时难以有效提升生成质量,已触及“预训练缩放瓶颈”。相比之下,融合高级语义理解(如引入图像-文本对比学习)的视觉分词器方案日益受到关注,其关键启示在于:对图像内容的理解能力是驱动生成质量提升的核心因素。这从原理上印证了“理解促进生成”的新一代视觉分词器设计方向。
一张图
Written on December 20, 2025